Combining Schemas
Schema stitching (@graphql-tools/stitch) creates a single GraphQL gateway schema from multiple underlying GraphQL services. Unlike schema merging, which simply combines local schema instances, stitching builds a combined proxy layer that delegates requests through to underlying service APIs. As of GraphQL Tools v7, stitching is fairly comparable to Apollo Federation with automated query planning, merged types, and declarative schema directives.
Note that schema stitching is a superset of the schema wrapping API. Rather than wrapping schemas individually and then combining them, stitchSchemas may be used directly to handle all wrapping concerns.
Why Stitching?
One of the main benefits of GraphQL is that we can query for all data in a single request to one schema. As that schema grows though, it may become preferable to break it up into separate modules or microservices that can be developed independently. We may also want to integrate the schemas we own with third-party schemas, allowing mashups with external data.

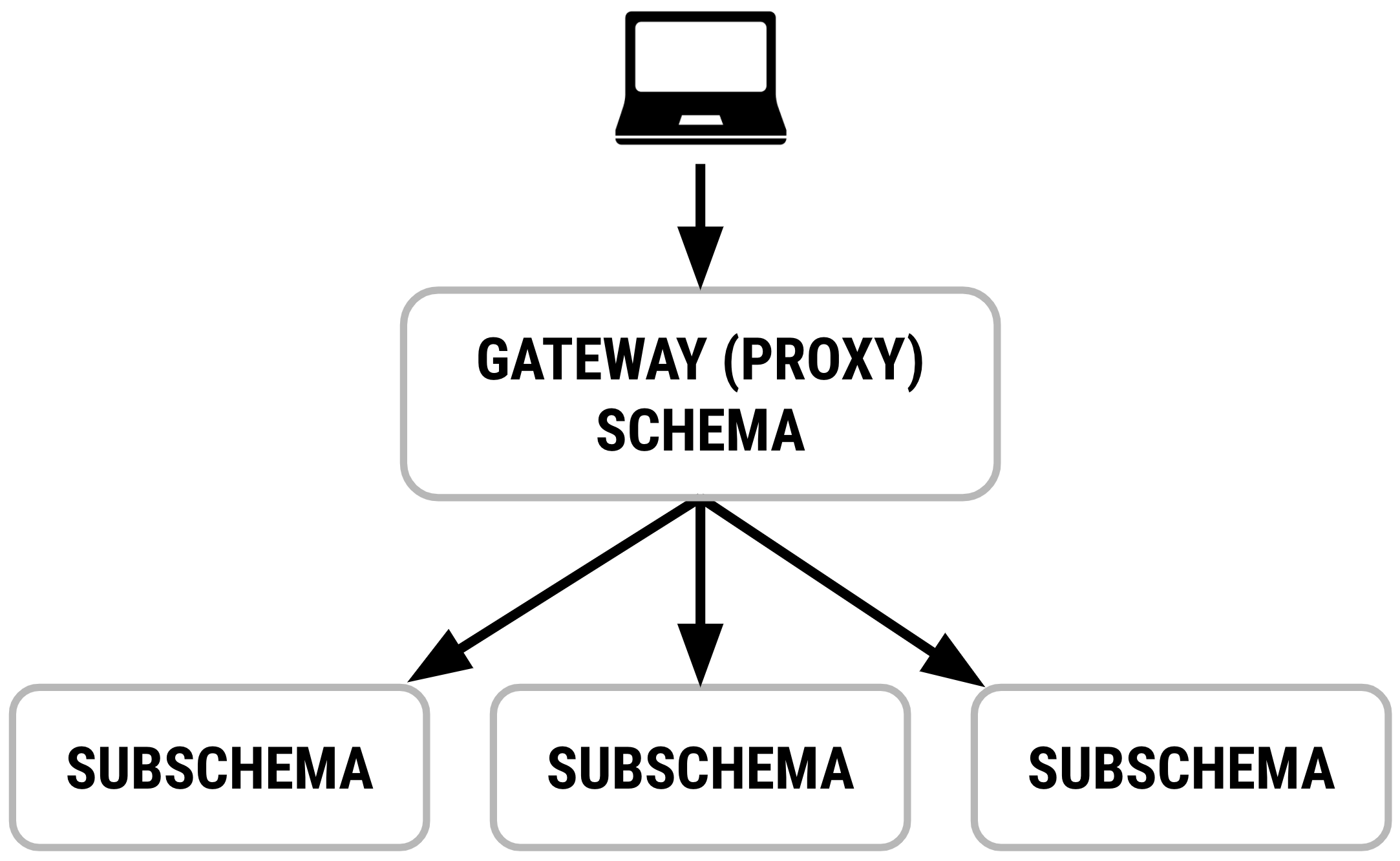
In these cases, stitchSchemas is used to combine multiple GraphQL APIs into one unified gateway proxy schema that knows how to delegate parts of a request to the relevant underlying subschemas. These subschemas may be local GraphQL instances or APIs running on remote servers.
Getting Started
In this example, we'll stitch together two very simple schemas representing a system of users and posts. You can find many supporting examples of stitching concepts in the Schema Stitching Handbook.
import { makeExecutableSchema } from '@graphql-tools/schema'
import { stitchSchemas } from '@graphql-tools/stitch'
let postsSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type Post {
id: ID!
text: String
userId: ID!
}
type Query {
postById(id: ID!): Post
postsByUserId(userId: ID!): [Post]!
}
`,
resolvers: {
// ...
}
})
let usersSchema = makeExecutableSchema({
typeDefs: /* GraphQL */ `
type User {
id: ID!
email: String
}
type Query {
userById(id: ID!): User
}
`,
resolvers: {
// ...
}
})
// setup subschema configurations
export const postsSubschema = { schema: postsSchema }
export const usersSubschema = { schema: usersSchema }
// build the combined schema
export const gatewaySchema = stitchSchemas({
subschemas: [postsSubschema, usersSubschema]
})This process builds two GraphQL schemas, places them each into subschema configuration wrappers (discussed below), and then passes the subschemas to stitchSchemas to produce one combined schema with the following root fields:
type Query {
postById(id: ID!): Post
postsByUserId(userId: ID!): [Post]!
userById(id: ID!): User
}We now have a single gateway schema that allows data from either subschema to be requested in the same query.
Subschema Configs
In the example above, the extra "subschema" wrapper objects may look verbose at first glance, but they are basic implementations of the SubschemaConfig interface that accepts several additional settings (discussed throughout this guide):
export interface SubschemaConfig {
schema: GraphQLSchema
executor?: Executor
createProxyingResolver?: CreateProxyingResolverFn
rootValue?: Record<string, any>
transforms?: Array<Transform>
merge?: Record<string, MergedTypeConfig>
batch?: boolean
batchingOptions?: {
extensionsReducer?: (mergedExtensions: Record<string, any>, request: Request) => Record<string, any>
dataLoaderOptions?: DataLoader.Options<K, V, C>
}
}Subschema config should directly provide as many settings as possible to avoid unnecessary layers of delegation. For example, while we could pre-wrap a subschema with transforms and a remote executor, that would be far less efficient than providing the schema, transforms, and executor options directly to subschema config.
Also note that these subschema config objects may need to be referenced again in other stitching contexts, such as schema extensions. With that in mind, you may want to export your subschema configs from their module(s).
Stitching Remote Schemas
To include a remote schema in the combined gateway, you must provide at least the schema and executor subschema config options.
import { introspectSchema } from '@graphql-tools/wrap'
import { fetch } from '@whatwg-node/fetch'
import { print } from 'graphql'
async function remoteExecutor({ document, variables }) {
const query = print(document)
const response = await fetch('https://my.remote.service/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query, variables })
})
return response.json()
}
export const postsSubschema = {
schema: await introspectSchema(remoteExecutor),
executor: remoteExecutor
}schema: this is a non-executable schema representing the remote API. The remote schema may be obtained using introspection, or fetched as a flat SDL string (from a server or repo) and built into a schema usingbuildSchema. Note that not all GraphQL servers enable introspection, and those that do will not include custom directives.executor: is a generic method that performs requests to a remote schema. It's quite simple to write your own. Subschema config uses the executor for query and mutation operations. See handbook example.
Duplicate Types
Stitching has two strategies for handling types duplicated across subschemas: an automatic merge strategy (default), and an older manual resolution strategy. You may select between these strategies using the mergeTypes option.
Automatic Merge
Types with the same name are automatically merged by default in GraphQL Tools v7. That means objects, interfaces, and input objects with the same name will consolidate their fields across subschemas, and unions/enums will consolidate all of their members. The combined gateway schema will then smartly delegate portions of a request to the proper origin subschema(s). See type merging guide for a comprehensive overview.
Automatic merging will only encounter conflicts on type descriptions and fields. By default, the final definition of a type or field found in the subschemas array is used, or a specific definition may be marked as canonical to prioritize it. You may customize all selection logic using typeMergingOptions; the following example prefers the first definition of each conflicting element found in the subschemas array:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
// ...
],
mergeTypes: true, // << default in v7
typeMergingOptions: {
// select a preferred type candidate to provide definitions:
typeCandidateMerger: candidates => candidate[0],
// and/or itemize the selection of other specific definitions:
typeDescriptionsMerger: candidates => candidate[0].type.description,
fieldConfigMerger: candidates => candidate[0].fieldConfig,
inputFieldConfigMerger: candidates => candidate[0].inputFieldConfig,
enumValueConfigMerger: candidates => candidate[0].enumValueConfig
}
})Merge Validations
The automatic merge strategy also validates the integrity of merged schemas. Validations may be set to error, warn, or off for the entire schema or scoped for specific types and fields:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
// ...
],
typeMergingOptions: {
validationSettings: {
validationLevel: 'error',
strictNullComparison: false, // << gateway "String" may proxy subschema "String!"
proxiableScalars: {
ID: ['String'] // << gateway "ID" may proxy subschema "String"
}
},
validationScopes: {
// scope to specific element paths
'User.id': {
validationLevel: 'warn',
strictNullComparison: true
}
}
}
})Manual Resolution
By setting mergeTypes: false, only the final description and fields for a type found in the subschemas array will be used, and automated query planning will be disabled. You may manually resolve differences between conflicting types with an onTypeConflict handler:
import { stitchSchemas } from '@graphql-tools/stitch'
const gatewaySchema = stitchSchemas({
subschemas: [
// ...
],
mergeTypes: false,
onTypeConflict: (left, right, info) => (info.left.schema.version >= info.right.schema.version ? left : right)
})Adding Transforms
Another strategy to avoid conflicts while combining schemas is to modify one or more of the subschemas using transforms. Transforming allows a schema to be groomed in such ways as adding namespaces, renaming types, or removing fields (to name a few) prior to stitching it into the combined gateway schema. These transforms should be added directly to subschema config:
import { FilterRootFields, RenameTypes } from '@graphql-tools/wrap'
const postsSubschema = {
schema: postsSchema,
transforms: [
new FilterRootFields((operation, rootField) => rootField !== 'postsByUserId'),
new RenameTypes(name => `Post_${name}`)
]
}In the example above, we transform the postsSchema by removing the postsByUserId root field and adding a Post_ prefix to all types in the schema. These modifications will only be present in the combined gateway schema.
Note that when automatically merging types, all transforms are applied prior to merging. That means transformed types will merge based on their transformed names within the combined gateway schema.
Error Handling
Whether you're merging types, using schema extensions, or simply combining schemas, any errors returned by a subschema will flow through the stitching process and report at their mapped output positions. It's fairly seamless to provide quality errors from a stitched schema by following some basic guidelines:
-
Report errors! Having a subschema return
nullwithout an error for missing or failed records is a poor development experience, to begin with. This omission will compound should an unexpected value produce a misleading failure in gateway stitching. Reporting proper GraphQL errors will contextualize failures in subschemas, and by extension, within the stitched schema. -
Map errors to array positions. When returning arrays of records (a common pattern while batch loading), make sure to return errors for specific array positions rather than erroring out the entire array. For example, an array should be resolved as:
posts() {
return [
{ id: '1', ... },
new NotFoundError(),
{ id: '3', ... }
];
}- Assure valid error paths. The GraphQL errors spec prescribes a
pathattribute mapping an error to its corresponding document position. Stitching uses these paths to remap subschema errors into the combined result. While GraphQL libraries should automatically configure thispathfor you, the accuracy may vary by programming language.